GS中的多线程
基础概念
- 并发和并行
- 吃饭吃到一半,电话来了,一直到吃完了以后才去接,这就说明你不支持并发也不支持并行。
- 吃饭吃到一半,电话来了,停了下来接了电话,接完后继续吃饭,这说明你支持并发。
- 吃饭吃到一半,电话来了,一边打电话一边吃饭,这说明你支持并行。
- 线程和协程:GS支持多线程,多协程,默认的调度器中有N个线程调度M个协程(一般M远大于N),一般N的个数会配置为略大于核数,启动时通过 /s 指定,如果过大,一个进程开了远多于核数的线程,会增加线程间切换的开销,对性能不会提升反而会下降;配得太小,无法充分利用多核性能,所以是略大于核数,具体还是看使用场景,如果有非常大量的IO操作,多开点线程还是有好处的
- 跨域/域锁:GS使用域(domain)来保证数据的多线程安全,一个域可以看成是一个互斥锁,当访问某个对象的时候,就会加锁,读写操作结束后再释放锁,这个过程称作跨域,
- RW/RO对象:普通对象都是RW(read-write)对象,即一定会和某个域绑定在一起,确保访问数据的线程安全,如果对象的文件中有#pragma parallel,说明是RO(read-only)对象,只能有parallel或readonly的成员变量,且所有方法都是parallel的
正确的并行
先来一个常见的错误的并行执行的示例,我们使用�最裸不带优化的计算素数作为示例:
void run()
{
// 希望10个协程并行计算不同阶段的素数
int step = 10000;
int co_num = 10;
array cos = [];
for (int i = 1 upto co_num)
cos.push_back(coroutine.create(0, (: foo, (i - 1) * step, i * step - 1 :)));
printf("Calc prime num (%d)\n", step * co_num);
int t = time.time_ms();
int sum = 0;
for (coroutine co : cos)
{
co.wait();
sum += co.get_ret();
}
printf("ret = %d, cost = %dms\n", sum, time.time_ms() - t);
}
int foo(int from, int to)
{
int num = 0;
for (int i = from; i <= to; ++i)
if (is_prime(i))
num ++;
return num;
}
bool is_prime(int v)
{
if (v < 2)
return false;
for (int i = 2 upto v - 1)
if (v % i == 0)
return false;
return true;
}
run();
输出的结果是:
Calc prime num (100000)
ret = 9592, cost = 3439ms
我们没有声明对象parallel,所以默认大家都跑在一个RW对象上,显然所以这些协程都会卡在当前这个对象的域,不能并行
那我们在对象中增加 #pragma parallell,是不是就可以了呢?跑了一下,结果还是一样,因为我们创建协程使用的coroutine.create默认会把当前域作为协程的入口域,虽然对象是parallel的,方法是parallel的,但是大家的入口是同一个域,所以还是不能并行
正确的做法是改成coroutine.create_with_domain
正确的示例:
#pragma parallel
void run()
{
// 希望10个协程并行计算不同阶段的素数
int step = 10000;
int co_num = 10;
array cos = [];
for (int i = 1 upto co_num)
cos.push_back(coroutine.create_with_domain(0, domain.create(), (: foo, (i - 1) * step, i * step - 1 :)));
printf("Calc prime num (%d)\n", step * co_num);
int t = time.time_ms();
int sum = 0;
for (coroutine co : cos)
{
co.wait();
sum += co.get_ret();
}
printf("ret = %d, cost = %dms\n", sum, time.time_ms() - t);
}
int foo(int from, int to)
{
int num = 0;
for (int i = from; i <= to; ++i)
if (is_prime(i))
num ++;
return num;
}
bool is_prime(int v)
{
if (v < 2)
return false;
for (int i = 2 upto v - 1)
if (v % i == 0)
return false;
return true;
}
run();
这样跑下来的结果是:
Calc prime num (100000)
ret = 9592, cost = 908ms
有个简化的写法,使用语法糖:@new:foo(),实际转调的是 coroutine.create_for_post_new
线程与协程
协程底层
GS语言中,线程和协程的底层实现在gcoroutine这个工程中,我们封装了一套和GS本身无关的协程库,最底层的协程调度有一套自己用汇编实现的,也有一套依赖ucontext和fiber的实现,目前实际使用的是依赖ucontext和fiber的实现,感觉更可靠一些,核心的底层resume/yield的代码见:
ContextWin ContextLinux 很简单,没几行代码,其余具体实现见:gcoroutine
协程调度
我们在上层封装了一层通过不同的调度器对协程进行调度的机制,比较常用的是并行调度器ParallelScheuler,顾名思义,使用多个线程去并行调度很多个协程,同一个协程可能在短时间内被不同的线程调度,反复横跳,底层也做了一些如果太久没有被调度到,就插到其他调度队列的实现,进行基础的负载均衡
上层通过coroutine.create或coroutine.create_with_domain来创建
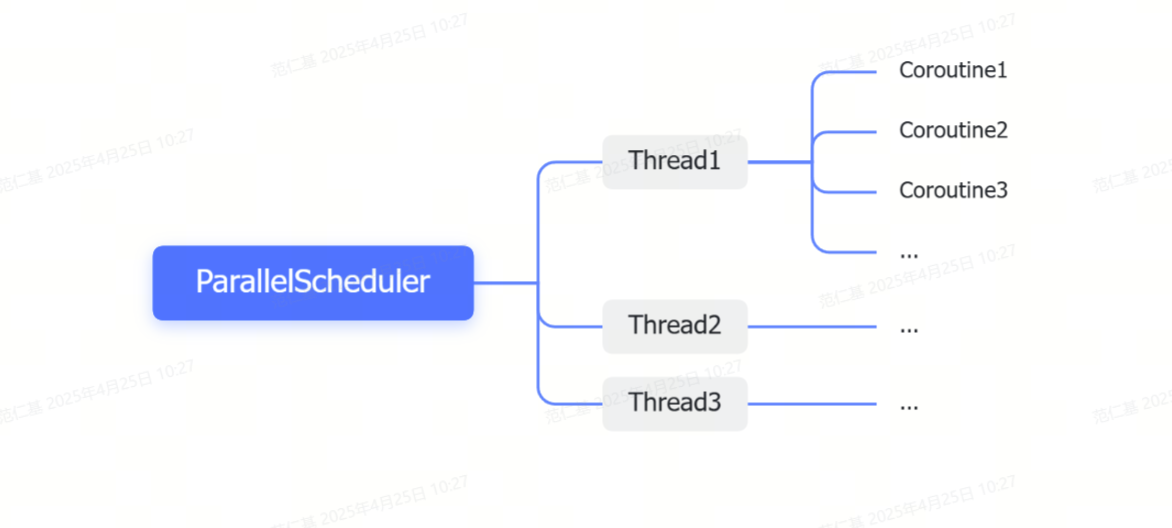
同时我们也有另一个调度器的实现,每个线程精准调度一个协程,保证这个协程不会因为调度而不能被及时执行,特别是在CPU比较忙的情况下,GS中通过coroutine.create_in_thread来创建
关于线程如何调度协程的细节,我们的实现和GO是类似的,但这些细节对于我们使用的影响不大,我们只要知道,协程是可以在真的不同的系统线程中执行的,只要执行时所在的域不同,大家就可以真的并行
只读与并行
对应GS中readonly和parallell两个关键字
readonly可以修饰成员变量
parallel可以修饰成员变量和方法
只读变量
readonly的变量,每次赋值都会深拷贝,如果写得很频繁,开销很大,出现过很多次ro变量频繁赋值导致的性能问题
void VmBase::do_RO_ASSIGN(Object* this_ob, ValueType type, ValueSubType sub_type, ValueAttrib attr, Value* p1, Value* p2)
{
// RO assign do not need to call check_before_write,
// since multiple assignments in different threads may occur
// at the same time, which will cause assertion in check_before_write
// Call this_ob->_check_after_written_no_assert() directly
// Assign to readonly object's var
// Allocate new readonly value if the value is reference value
if (p2->is_reference_value() && p2->m_reference->is_modifiable())
{
// Clone the source value & make it readonly
auto* current_domain = Coroutine::get_current_co_domain();
CO_VALUE(cloned_val);
p2->clone_entirely(&cloned_val, current_domain, current_domain);
ReferenceRoParallel::make_readonly(&cloned_val);
_check_and_assign(type, sub_type, attr, p1, &cloned_val);
}
else
_check_and_assign(type, sub_type, attr, p1, p2);
// Notify this_ob was changed if it an old unit
this_ob->_check_after_written_no_assert();
}
举个例子:
map m = get_system_info();
void run()
{
map s = get_system_info();
int t = time.time_ms();
for (int i = 1 upto 1000000)
m = s;
t = time.time_ms() - t;
printf("t = %dms\n", t);
}
run();
输出结果:
t = 12ms
readonly map m := get_system_info();
void run()
{
map s = get_system_info();
int t = time.time_ms();
for (int i = 1 upto 1000000)
m := s;
t = time.time_ms() - t;
printf("t = %dms\n", t);
}
run();
输出结果:
t = 1273ms
并行变量
parallel变量,如果是个容器(map或者array),可以并行读写容器中的某个元素,但是如果容器本身要改变(添加或减少元素)就需要重新类似RO变量那样做一次深拷贝
parallel变量实现的目的就是改进RO变量的性能,在很多场景下,我们容器中元素的数量是稳定的,只是元素要频繁变动,这种情况没必要每次写都深拷贝,可以使用share_value,但是使用起来麻烦,并且也有读写加锁的开销,及时有读写锁,还是比直接访问慢不少
举个例子,我们把每一段的结果分别存起来,存在一个数组中,这是个比较常见的应用场景
#pragma parallel
const int SLICE = 10;
parallel array _multi_results := make_parallel(array.allocate(SLICE, 0));
int run()
{
int step = 10000;
int co_num = SLICE;
array cos = [];
for (int i = 1 upto co_num)
cos.push_back(coroutine.create_with_domain(0, domain.create(), (: foo, i - 1, (i - 1) * step, i * step - 1 :)));
printf("Calc prime num (%d)\n", step * co_num);
int t = time.time_ms();
int sum = 0;
for (coroutine co : cos)
{
co.wait();
sum += co.get_ret();
}
printf("ret = %d, cost = %dms\n", sum, time.time_ms() - t);
printf("rets = %O\n", _multi_results);
return sum;
}
int foo(int n, int from, int to)
{
int num = 0;
for (int i = from; i <= to; ++i)
if (is_prime(i))
num ++;
_multi_results[n] := num;
return num;
}
bool is_prime(int v)
{
if (v < 2)
return false;
for (int i = 2 upto v - 1)
if (v % i == 0)
return false;
return true;
}
run();
关于性能方面,有些情况下会比RO变量好非常多
readonly map m := get_system_info();
void run()
{
int t = time.time_ms();
for (int i = 1 upto 1000000)
{
m := m + {"jit_type" : i};
}
t = time.time_ms() - t;
printf("t = %dms\n", t);
}
run();
运行结果是:
t = 2540ms
parallel map m := make_parallel(get_system_info());
void run()
{
int t = time.time_ms();
for (int i = 1 upto 1000000)
{
m["jit_type"] := i;
}
t = time.time_ms() - t;
printf("t = %dms\n", t);
}
run();
运行结果是:
t = 25ms
并行方法
- 定义:在RO对象中(有#pragma parallel的对象)中的方法,或者方法声明时带了parallel修饰是并行方法,调用并行方法不需要跨域,不同的协程可以进行并行调用
- 限制:在普通RW对象中的parallel方法不能访问普通(非readonly或者parallel)的成员变量
- 目的:利用多线程并行计算进行优化
- 难点:函数变量的参数域,具体参考: 函数变量的参数域
- 设计初衷:底层增加限制,确保不会因为跨域拷贝,导致行为和直觉不符,比如一个函数会改变栈上的变量,那么我们希望不管怎么传,传到哪个域,有没有拷贝,这个函数都被调用的时候都能改变这个栈上的变量,否则行为和直觉就会违背
性能简单测试下:
string src = """P
public void foo() {}
public parallel void foo_parallel() {}
"""P;
void run()
{
compile_program("/xx.gs", src);
object ob = new_object("/xx.gs", domain.create());
int t = time.time_ms();
for (int i = 1 upto 5000000)
ob.foo_parallel();
t = time.time_ms() - t;
printf("t = %dms\n", t);
}
run();
运行结果是:
t = 142ms
string src = """P
public void foo() {}
public parallel void foo_parallel() {}
"""P;
void run()
{
compile_program("/xx.gs", src);
object ob = new_object("/xx.gs", domain.create());
int t = time.time_ms();
for (int i = 1 upto 5000000)
ob=>foo();
t = time.time_ms() - t;
printf("t = %dms\n", t);
}
run();
运行结果是:
t = 384ms
这种简单调用的情况下确实快不少,但是快得也有限
换一种情况,如果我们有个map要作为参数呢?
string src = """P
public void foo(mixed m) {}
public parallel void foo_parallel(mixed m) {}
"""P;
void run()
{
compile_program("/xx.gs", src);
object ob = new_object("/xx.gs", domain.create());
int t = time.time_ms();
map m = get_system_info();
for (int i = 1 upto 5000000)
ob.foo_parallel(m);
t = time.time_ms() - t;
printf("t = %dms\n", t);
}
run();
运行结果是:
t = 196ms
看上去和不传参数也差不多,再试试跨域的版本
string src = """P
public void foo(mixed m) {}
public parallel void foo_parallel(mixed m) {}
"""P;
void run()
{
compile_program("/xx.gs", src);
object ob = new_object("/xx.gs", domain.create());
int t = time.time_ms();
map m = get_system_info();
for (int i = 1 upto 5000000)
ob=>foo(m);
t = time.time_ms() - t;
printf("t = %dms\n", t);
}
run();
运行结果是,有质的�差别,主要就在于跨域需要dup参数
t = 4746ms
跨域调用
跨域实现
具体实现见:
Coroutine::try_switch_object_domain
核心流程:

可以总结以下几点:
- 跨域调用总是会拷贝参数,即使实际没有切域
- 跨域调用的返回值也一定会拷贝
- 跨域调用类比在C++使用mutext保护,效率会更高些,在冲突不多的情况下,只有个原子操作的消耗
- 跨域的时候会离开当前域
避免死锁
我们有个机制是,再进入一个协程的时候必须释放当前域锁,所以是不会出现死锁的情况的
- 互斥:某种资源一次只允许一个进程访问,即该资源一旦分配给某个进程,其他进程就不能再访问,直到该进程访问结束。
- 占有且等待:一个进程本身占有资源(一种或多种),同时还有资源未得到满足,正在等待其他进程释放该资源。
- 不可抢占:别人已经占有了某项资源,你不能因为自己也需要该资源,就去把别人的资源抢过来。
- 循环等待:存在一个进程链,使得每个进程都占有下一个进程所需的至少一种资源。
域锁在每次锁定前释放当前域的特性就是为了打破了第二个条件
我们后来还支持过一版需要指定每个域的优先级,��限制只能锁定比当前更高级的域,保证锁定的书序,这样避免出现 thread1: A lock B,thread2: B lock A 这样带来的死锁,但是由于开发起来心智负担过重,废弃了,代码逻辑还在,只是没用实际使用
禁止跨域
有些情况下,我们希望在一段时间内禁止跨域,避免过程中产生意料之外的状态改变,比如在循环的过程中
方法1,try_lock(this),把自己try_lock住,try_lock期间一旦跨域就会报错
try_lock(this)
{
for (mixed m : container)
{
// 中间所有跨域都会报错
....
}
}
方法2,在当前协程上增加NO_PEND标记
auto co = this_coroutine();
int attr = co.get_attrib();
co.set_attrib(attr | CoAttrib.NO_PEND);
defer co.set_attrib(attr);
// 这个应该是防止sleep
// 此后所有跨域都会报错
....
方法3,使用force_lock
this_domain.force_lock(true);
defer this_domain.force_lock(false);
// 此后所有跨域都会报错
...
多线程GC
一句话概括:依赖GC写屏障,消除STW,达到并行GC的目的
本文只简单介绍一下流程思路和其中用到的多线程相关的特性,之后有机会再把细节展开
检查点
// 几个枚举的定义
// Control flags
enum class Control : Uint8
{
WALK_THROUGH = 0x01, // Auto reset this flag in check_control()
NO_TRIGGER = 0x02, // Assertion flag: don't enter check_control()
SUSPEND = 0x04, // Suspend current coroutine
TO_WORK_FOR_GC = 0x10, // To work as work_thread until GC finisheds
CALLBACK_IN_CC = 0x20, // Has callback in check control
TERMINATE = 0x80, // Termiante this coroutine
};
// Stage of gc
enum class Stage : Int8
{
IDLE = 0,
PREPARING = 1,
MARKING_ALL = 2,
STOPPING_MARKING = 3,
SWEEPING = 4,
UPDATE_NEW_ALLOC = 5,
};
// coroutine类
class Coroutine
{
// ....
// Control flags
Control volatile m_control;
// Add control
void add_control(Control flags)
{
std_cpu_lock_or_fetch8(&m_control, flags);
}
// Set attrib
Control Coroutine::get_control() const
{
return m_control;
}
}
// GC::WordManager类
class WorkManager
{
// Switch to new stage
void switch_stage(Stage new_stage)
{
m_stage_ex.working_stage = new_stage;
}
}
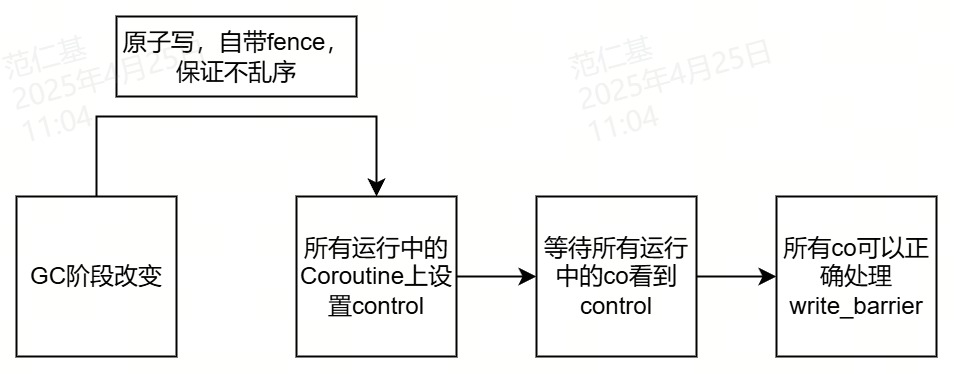
等待所有运行中的协程看到GC的检查点
// Set control flag to all coroutines
void GC::wait_until_all_running_coroutines_are_walked_through()
{
std_cpu_mfence();
auto ptrs = Coroutine::get_all_running_co_ptrs_by_gc();
// Skip gc_main & non-gc coroutines
// Set control flag: WALK_THROUGH
size_t k = 0;
for (size_t i = 0; i < ptrs.size(); i++)
{
auto* co = ptrs[i];
if (co->has_attrib(Coroutine::SKIP_WALK_THROUGH |
Coroutine::WORKING_IN_GC))
{
// Skip this co
continue;
}
ptrs[k++] = co;
co->add_control(Coroutine::Control::WALK_THROUGH);
GC_TRACE("[%s] Set control flag(%d) for %s(%s).\n",
Coroutine::get_current_co_name().c_str(),
(int)control_flag,
co->get_name().c_str(),
co->get_id().to_string().c_str());
}
ptrs.resize(k);
// Wait until coroutines are finished
for (auto co : ptrs)
{
STD_ASSERT_MSG(co != m_gc_main_co,
"These coroutines should be removed when set flag.");
// Wait this coroutine processed control flag or state is not
// RUNNING or ENDING
// ATTENTION:
// For an ENDING coroutine, we must wait it to be ENDED. or the
// coroutine may put itself to changed set
auto tick = std_get_os_tick();
bool logged = false;
while ((co->is_running_not_waiting() || co->is_ending()) &&
co->has_control(Coroutine::Control::WALK_THROUGH))
{
if (!logged && std_get_os_tick() - tick > 500) // 0.5s
{
stdstr_t str;
str.snprintf("Warning: Coroutine %s running too long (>0.5s) without any check_control().\n",
256, co->handle_to_string().c_str());
Coroutine::log_callstack(str, co);
logged = true;
}
// Wait
std_sleep(0);
}
}
}
This function generates a full memory barrier (or fence) to ensure that memory operations are completed in order.
在gc线程给运行中的coroutine加上这个标记,并等待所有运行中的coroutine都看到这个标记后再继续往下,保证所有线程对这块内存的改动可见,由于add_control用了原子写(带屏障),内存可见性的顺序是有保证的,当某个线程看到了m_control的改动,那么对于m_control之前写的内存一定也可见了,所以对于所有线程来讲,一定能看到WorkManager上m_stage的值,得到正确GC阶段,从而正确地通过写屏障
更多细节,可以参考内存模型相关的资料
- Memory model - cppreference.com
- std::memory_order - cppreference.com
写屏障
可回收单元在写之前,一定要通过写屏障,如果在Marking过程中就地标记
// Write barrier: marking the unit when gc is marking
static void unit_write_barrier(const GCUnitBase* unit)
{
if (!gc_is_marking())
// GC is not marking now
return;
auto* desc_addr = unit->unit_get_desc_addr();
if (unit->unit_is_black(desc_addr))
// Already marked, skip
return;
gc_local_pool_reference_to_white_unit(unit);
- 关于并行GC的参考:
- 其他参考
内存乱序
TODO